February 18, 2020
Precision Medicine - Datasets


The fields of genetics and bioinformatics are producing troves of data with enormous value to human health. Topcoder has made datasets associated with our work in this space accessible to allow our community to gain experience with the processes and challenges to working with this type of data.
Dataset Links
1000 Genomes Project Subsampling Data
Topcoder made use of a random sampling of data from the 1000 Genomes Project to create a Genotype matrix
Download

Offline GWAS Tester Tool
The offline testger can run your solution locally and calculate its raw score. We also provide the Java source code of the offline tester. You are allowed to introduce any modifications into the code in order to make it suit your needs better.
Visit Page

Connectivity Map: Landmark Gene Training Data
100,000 samples of 12,320 genes. The first 970 rows are the landmark genes and the last 11,350 are the non-landmark genes.
Download
Connectivity Map: Landmark Gene Testing Data
This testing data contains 1,650 samples with the landmark genes measured by L1000
Download
History of Our Work
GWAS Speedup
Modeling associations between markers and phenotypes can be complex because of the need to take into account confounding covariates and model non-quantitative traits (e.g., case vs. control status). This contest focused on speeding up the logistic regression modeling that is the most computationally demanding component of many GWAS analyses.
Visit Page
CMAP Generation and Analysis of Gene Expression Signatures
The goal of contest on was to maximize the accuracy of the inferred gene expression values while minimizing the number of measured gene expressions. Results will further expand horizons for computational biologists and scientists who seek to find drugs that cure diseases.
Visit Page
CMAP 2 - Acceleration of CMAP Algorithm
The second challenge in the 2016 Connectivity Map series asked competitors to speed up the existing CMAP algorithm.
Visit Page
CMAP 3 - DPeak Challenge
In this challenge we sought to improve the speed and accuracy of ‘dpeak’, the algorithm that deconvolutes the composite expression signal into two values and associates them with the appropriate genes. These improvements will enable CMap to produce higher quality data more efficiently.
Visit Page
Blogs and Discussions

Topcoder Customer Stories - GWAS Algorithm Optimization
A pharma company’s GWAS analysis solution had proven to be accurate, yet it hampered researches due to the long run time on each experiment they administered. They wanted to speed up the logistic regression modeling — the most computationally demanding component of many GWAS analyses — that determines which markers explain specific phenotypes.
Visit Page

Topcoder Customer Stories - DNA Sequencing Algorithm
Renowned for its innovation in medical research and genomics, Harvard Medical School wanted to speed the process of standard DNA sequencing, which is essential for making precise, high-throughput readouts of the immune system. A full-time employee had worked for a year to optimize an algorithm that calculates the distance between DNA strings, but they wanted to see if more data scientists working on the problem could deliver even better results.
Visit Page
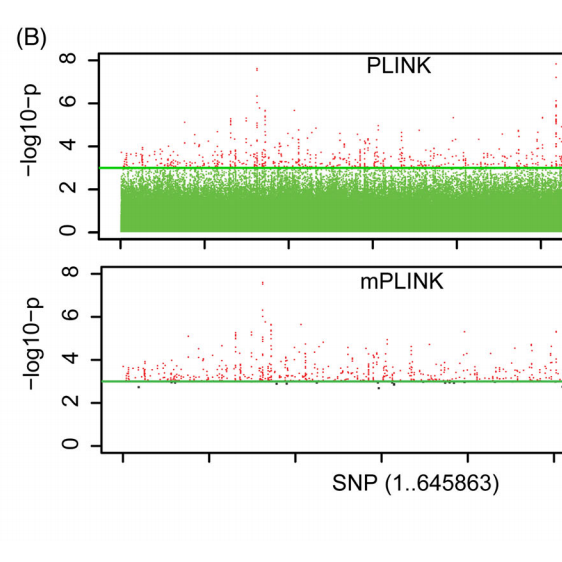
Oxford GigaScience - Stepwise Distributed Open Innovation Contests for Software Development: Acceleration of Genome-Wide Association Analysis
Through a crowd-based contest a combination of computational, numeric, and algorithmic approaches was identified that accelerated the logistic regression in PLINK 1.07 by 18- to 45-fold
Visit Page
3
0